
By: Amira Burns, Hailey Wilmer, and Ryan S. Miller | 10/30/2023 ARS SCINet Fellow, ARS Research Rangeland Management Specialist, and APHIS-CEAH Senior Ecologist
The use of camera traps is a popular and cost-effective way to monitor animal populations, evaluate animal behavior, and study ecological processes influencing populations. However, a camera trap dataset for a single site or research question can result in millions of images that require classification to be useful for analysis. The USDA-ARS Range Sheep Production Efficiency Research Unit (Dubois, ID) has joined the USDA Animal and Plant Health Inspection Service’s Center for Epidemiology and Animal Health (APHIS-CEAH) to continue developing CameraTrapDetectoR, an open-source tool that deploys deep learning object detection models to detect, classify, and count animals in camera trap images.
 Figure 1. Prediction plots from CameraTrapDetectoR models (species, family, and class)
Figure 1. Prediction plots from CameraTrapDetectoR models (species, family, and class)
CameraTrapDetectoR is free, easy to use, allows a user to retain full control of their data and can be incorporated into analytical pipelines easily. The models can be used via the CameraTrapDetectoR R package, which includes an R Shiny application to deploy models with minimal coding; a desktop app that wraps an R installation and R Shiny application and requires no coding; or via a Python script that runs on the command line and is ideal for utilizing GPUs and running the models on SCINet. The R package also provides a suite of functions to assist with data organization and post-processing. CameraTrapDetectoR consists of six independently trained object detection models at three taxonomic levels: a general class model that detects mammals and birds, a family-level model that includes 31 taxonomic families, and a species-level model that includes 75 species. Each model also includes classes for humans, vehicles, and empty images. The current (second) generation of models was trained using a Faster R-CNN model architecture with a ResNet-50 feature pyramid network backbone on the Atlas cluster’s GPU nodes. The current verified training set contains 282,188 images contributed from over 30 participant groups across ARS, APHIS, and other government agencies and academic or private partners.
The continued development of the CameraTrapDetectoR is based on an iterative training cycle (Fig. 2), with different stages often progressing simultaneously. For example, our team is currently finalizing annotations on a new series of images (step 2) to incorporate into a third generation of models, testing updated object detection algorithms (step 3), and adding model results to image metadata to assist post-processing analyses (step 5). SCINet is a critical tool throughout the training process, and development of these models would not be possible without a high-performance computing cluster. In addition to training models and generating predictions on new data, we use SCINet to transfer images and collaborate with project contributors in the SCINet community.
Sophisticated image analysis algorithms and data processing techniques have limited impact on the challenges of accurate detection and classification without a robust, diverse database of training images. CameraTrapDetectoR’s most powerful asset is the growing team of researchers who share camera trap datasets for the sole purpose of model evaluation and training and provide essential feedback on the tool’s user interface and development direction. Our team would like to continue expanding within the SCINet community; please contact us via email or through our Github page for more information.
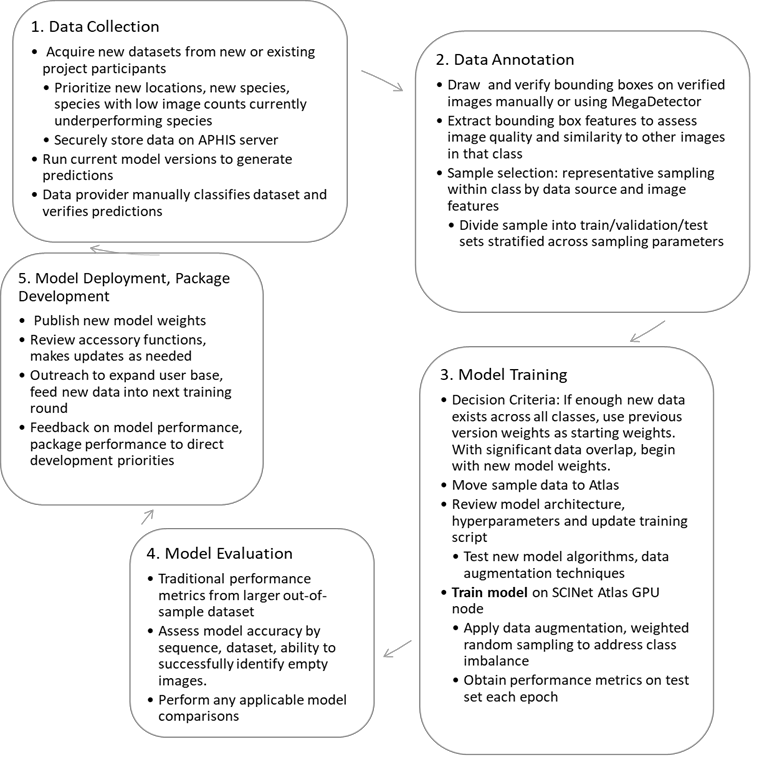 Figure 2. CameraTrapDetectoR Iterative Training Cycle
Figure 2. CameraTrapDetectoR Iterative Training Cycle