
High-Performance Computing. Training. High-Speed Networking.
What is SCINet?
The SCINet initiative is an effort by the USDA Agricultural Research Service (ARS) to grow USDA’s research capacity by providing scientists with access to high-performance computing clusters, high-speed networking for data transfer, and training in scientific computing.
Upcoming Trainings and Events
-
Bioinformatics Foundations · Automating Bioinformatics Pipelines with Snakemake
This hands-on workshop introduces Snakemake, a workflow management system that brings the readability of Python to scalable, reproducible computational pipelines. We will start with foundational examples and build to a real-world bioinformatics pipeline — learning how Snakemake’s rule-based, file-driven approach automatically determines job dependencies, handles parallel execution, and integrates seamlessly with Python scripts and virtual environments to produce publication-ready outputs.
-
SCINet Corner · Managing storage quotas on SCINet
The SCINet Corner is a recurring virtual gathering to provide a space for people to meet and discuss SCINet-related items.
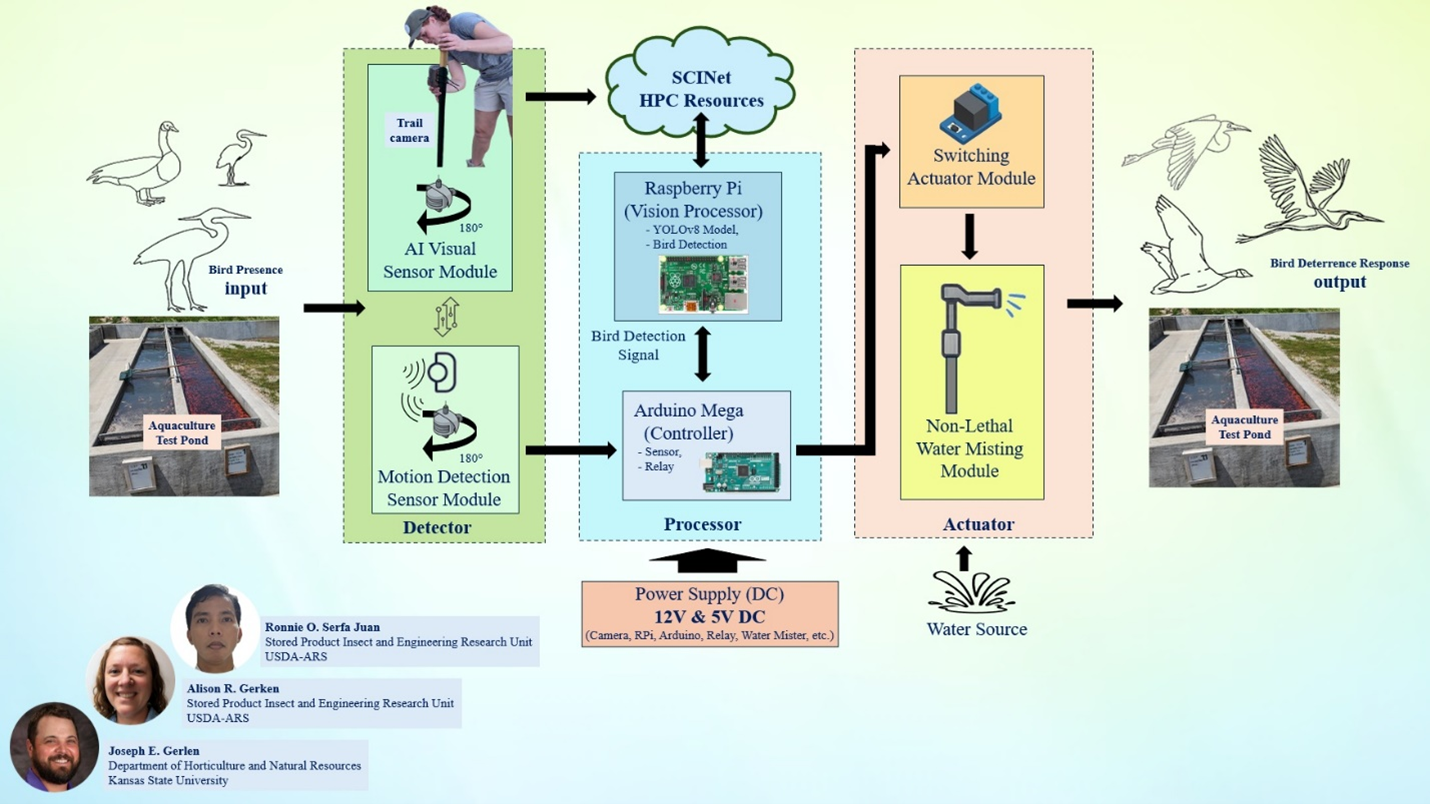
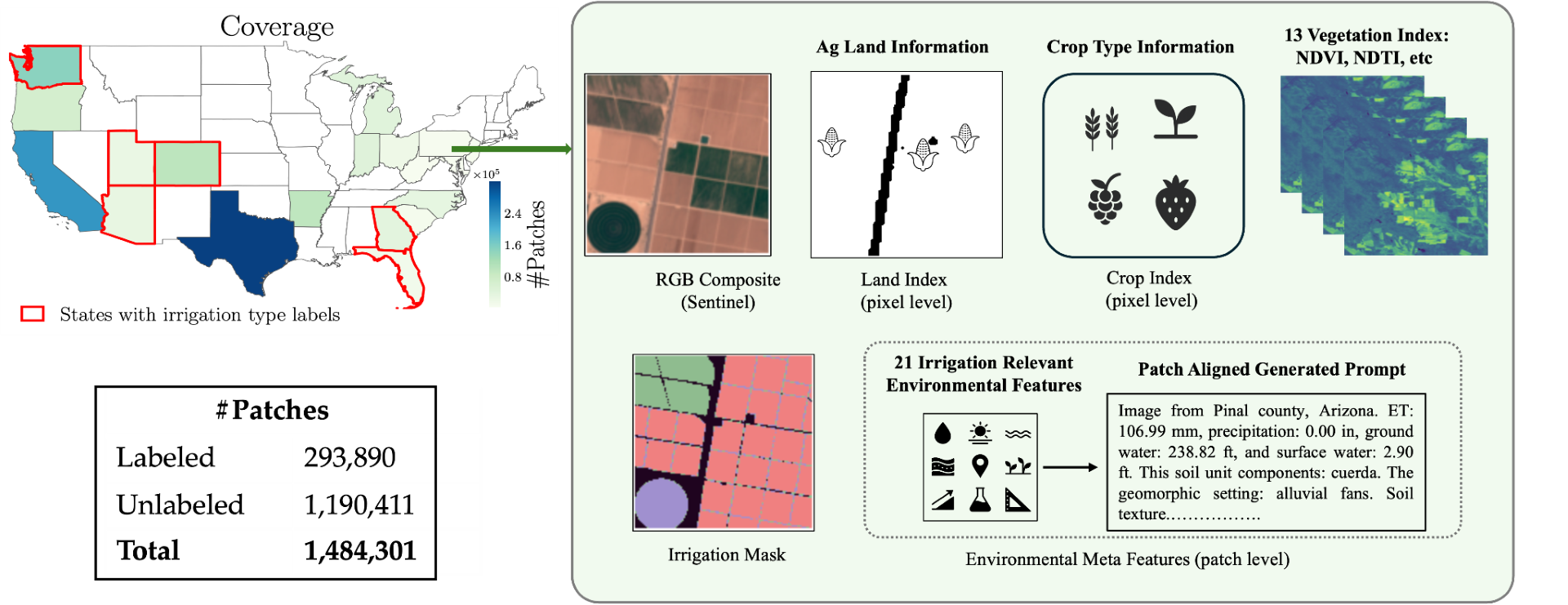

Find out how SCINet can enable your research
-
Working Groups
Information about how our collaborators currently use SCINet
-
Fellowship Opportunities
SCINet-funded research fellowship opportunities for PhD and MS level graduates
-
How to Use SCINet
Quick Start guide to getting up and running with SCINet
-
Running Analyses
Guides for running different analyses
-
Frequently Asked Questions
Answers to common questions asked about SCINet
-
Need Help?
Find who you need to contact for specific issues or requests