
This document describes recommended procedures (SOP) for managing data on ARS HPC and storage infrastructure. The key concept is to only use “Tier 1 storage” (that is, storage that is local to a given HPC cluster) as required for actively running compute jobs. Tier 1 storage is not backed up and should not be used for archival purposes. Juno, on the other hand, is periodically backed up to tape and can be used for long-term storage of data and results. We recommend immediate adoption of the procedures described here for new projects. These procedures should also be followed for “old” projects after first moving extant project data in Tier 1 storage to Juno using one of the procedures described below. If you would like more detailed information about the data storage options provided by SCINet and how to use them, please see the SCINet Storage Guide.
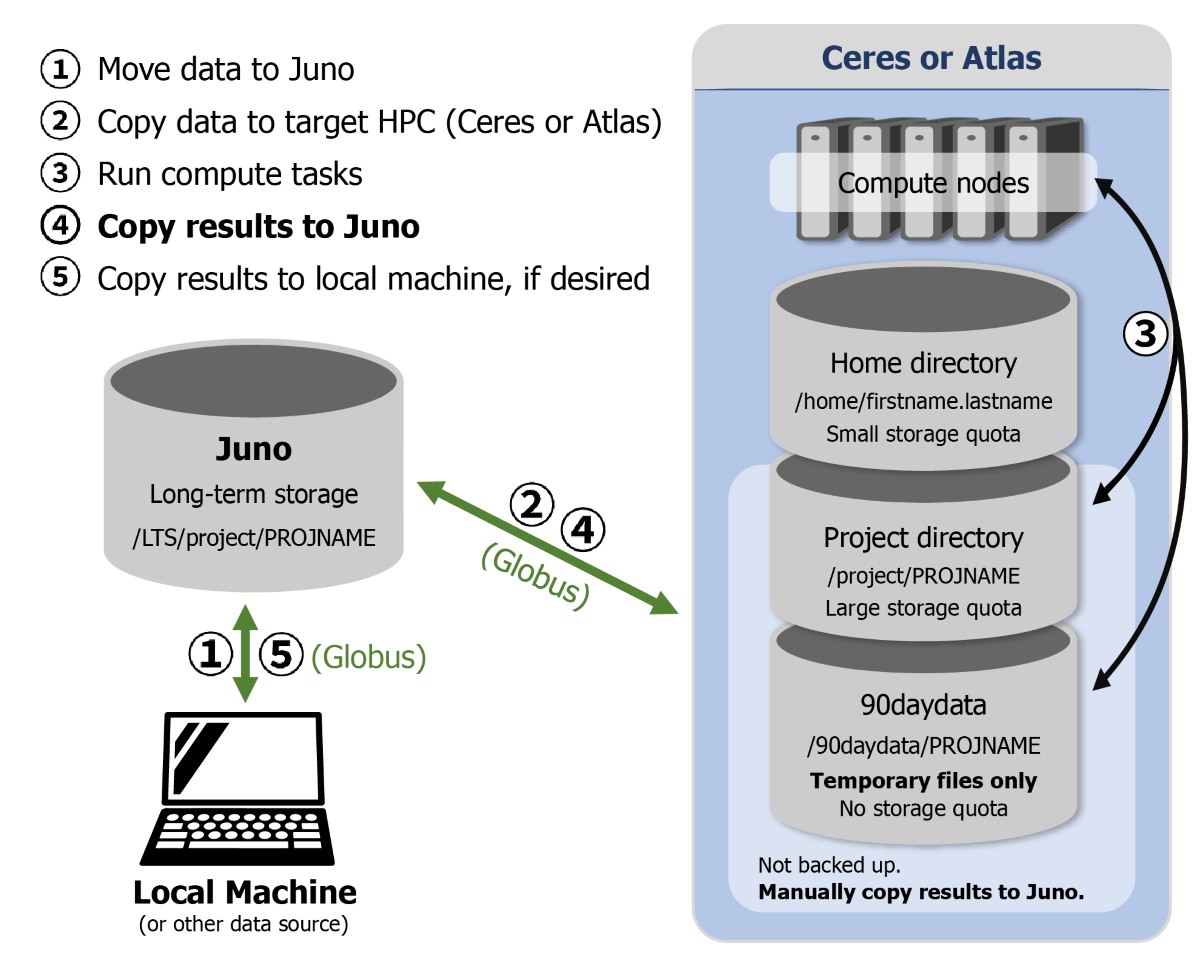 Figure 1. Recommended procedures for managing data on ARS HPC infrastructure using Globus.
Figure 1. Recommended procedures for managing data on ARS HPC infrastructure using Globus.
- Move data to Juno
- Copy data to target HPC (Ceres or Atlas)
- Run compute tasks
- Copy Results to Juno
- Copy results to local machine, if desired
Definitions
- Juno: Large, multi-petabyte ARS storage device at the National Agricultural Library in Maryland, accessed by users; periodically backed up to tape device. Includes periodic file system snapshots that allow users to recover accidentally deleted files.
- Tape backup: Off-site backup of Juno, located at Mississippi State University, accessible by VRSC staff for disaster recovery following major system data loss.
- Tier 1 Storage: Storage on either of the HPC clusters, local to computing resources at the National Centers for Animal Health in Ames, Iowa or Mississippi State University. These locations are for storing code, data, and intermediate results while performing a series of computational jobs. This storage is not backed up. Two storage locations are available on each HPC cluster,
/projectand/90daydata. Historically, space had routinely been allocated in/project, but going forward, space in/projectwill only be allocated on an as-needed basis. Most users should use/90daydatafor routine Tier 1 storage.
Detailed instructions, using Globus (preferred)
Using Globus is recommended for file transfer performance and reliability. The recommended data management workflow using Globus is illustrated in Figure 1, above.
See the SCINet Globus Data Transfer guide for instructions on how to use Globus.
- Copy raw data and custom software (e.g., custom scripts, ideally also versioned in Git repositories; conda environments/environment.yml, Singularity image/definition files) from a local workstation or other data source to a project directory on Juno using Globus (search for Globus collection “SCINet-Juno”) (Figure 1.1). On Juno, the data should be copied to
/LTS/project/PROJNAME/. - If not already there, copy data to Tier 1 storage on the cluster you will run on, either Ceres or Atlas, using Globus. For most projects, you should use
/90dayadatafor routine, short-term storage (Figure 1.2). There are no storage quotas on/90daydata, so it is ideal for data-intensive work. For projects that require longer-term use of Tier 1 storage, space can be requested in/project. However, please note that no data on Tier 1 storage is backed up. - Use ssh to log in to your chosen HPC cluster (Ceres or Atlas; see Logging in to SCINet); (e.g.:
ssh FIRST.LAST@ceres.scinet.usda.gov) and run your compute job (Figure 1.3).
- Copy any results you need to keep to Juno so that they are preserved (Figure 1.4).
- If desired, you can also copy results to your local workstation (Figure 1.5).
Note that step 1 might not be necessary for all data used for a project. For example, suppose you need to use a large, publicly available satellite-derived dataset for a project. In this case, the data probably do not need to be stored on Juno and can simply be placed directly in
/90daydataon Tier 1 storage and deleted when they are no longer needed.
Alternative instructions, not using Globus
It is also possible to move data on SCINet infrastructure using traditional command-line tools like scp and rsync. See the SCINet File Transfer guide for instructions on how to use these commands to transfer data to/from Ceres and Atlas cluster.
To move data to/from Juno, login to ceres-dtn and issue scp or rsync command to nal-dtn, e.g.:
ssh ceres-dtn
rsync -avz --no-p --no-g ttt nal-dtn.scinet.usda.gov:/LTS/project/<project_name>/
Please note that in order to access Juno via the command line, you must first connect to Ceres. Then, you can connect to Juno by issuing the following:
ssh nal-dtn.scinet.usda.gov